前言
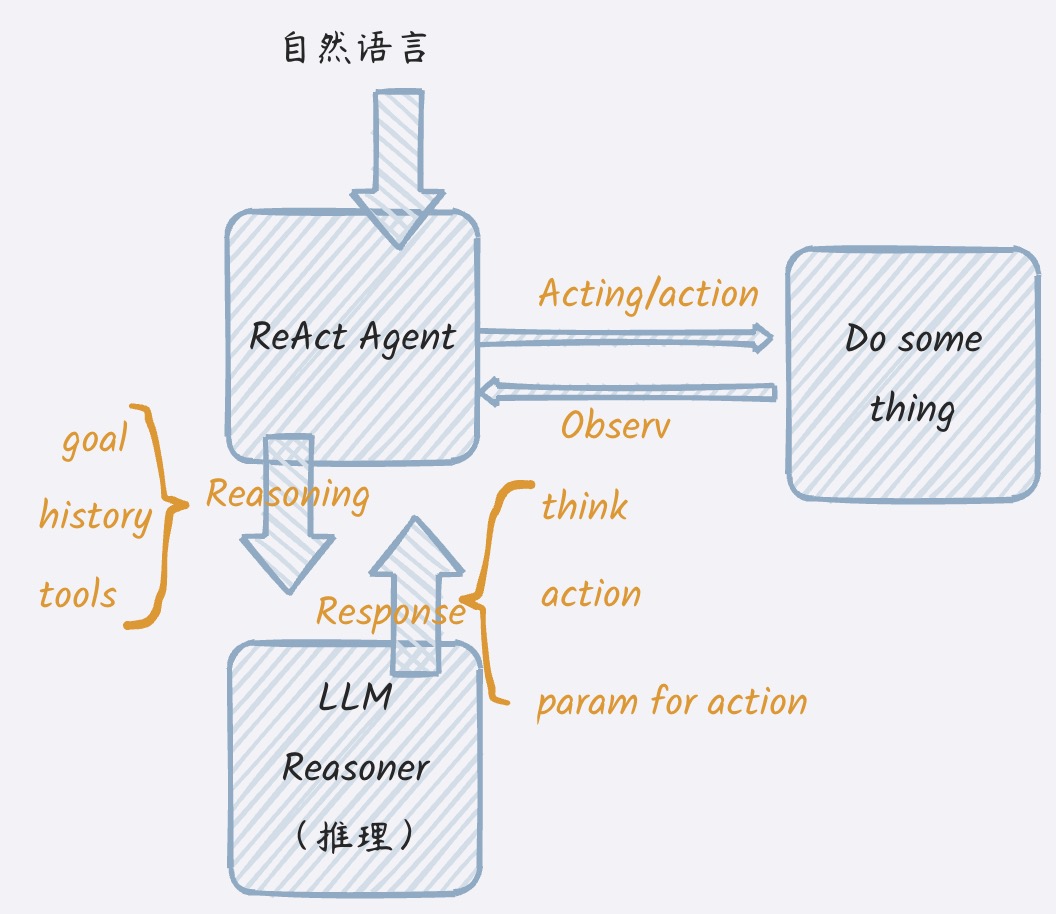
如果一个ReAct框架的程序大概长这样(如下图架构),那么LLM Reasoner这个类通常有两件最重要的事情要做
- 初始化大模型,简称init()
- 调用大模型进行推理,简称reason()
如何设计LLM Reasoner这个类,使他可以更方便的支持多个大模型(比如deepseek,Gemini,OpenAI等)
方式一、简单工厂模式

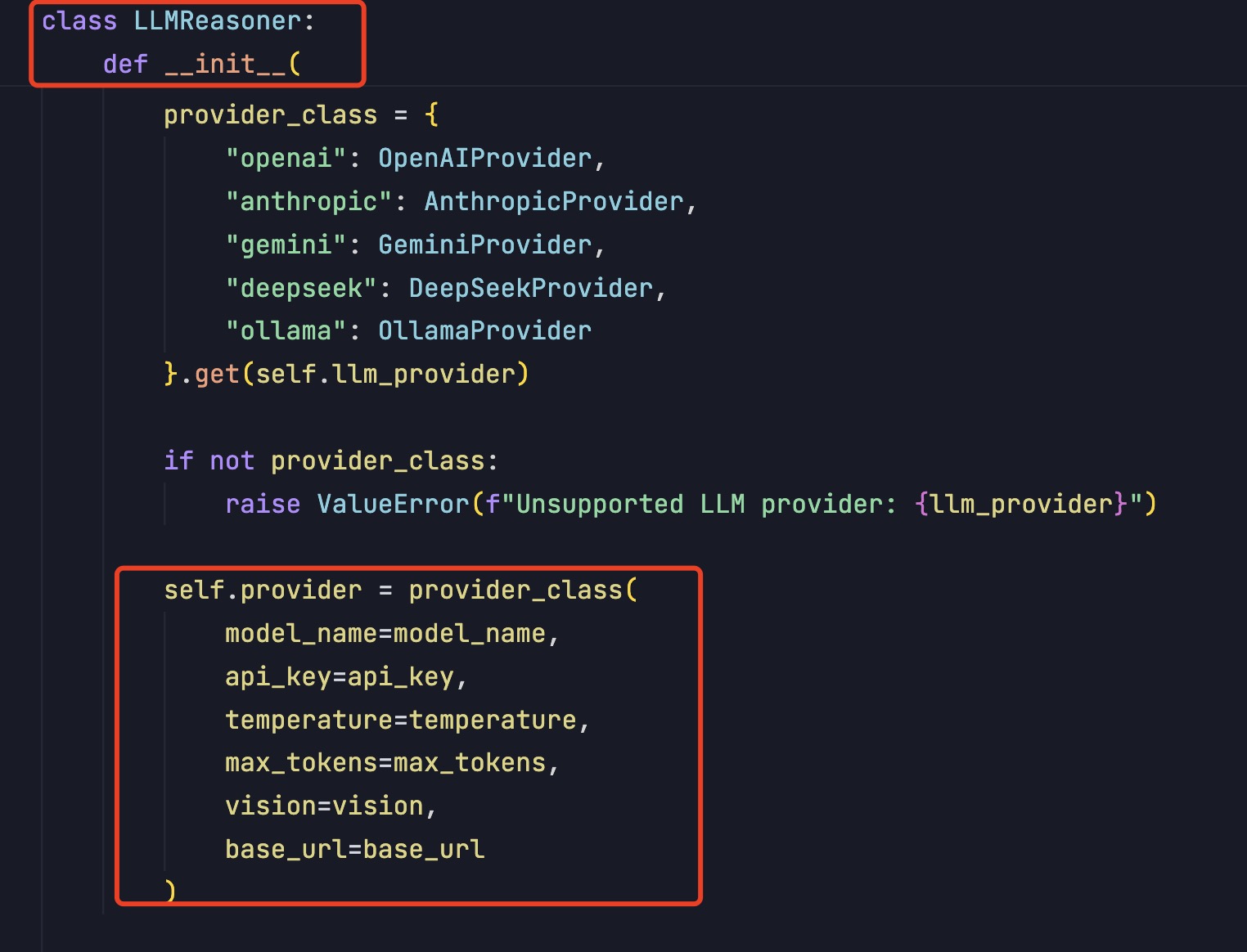
把不同大模型init和reason的代码,硬编码到上图LLMReasoner类的init方法和reason方法中,就像这样。
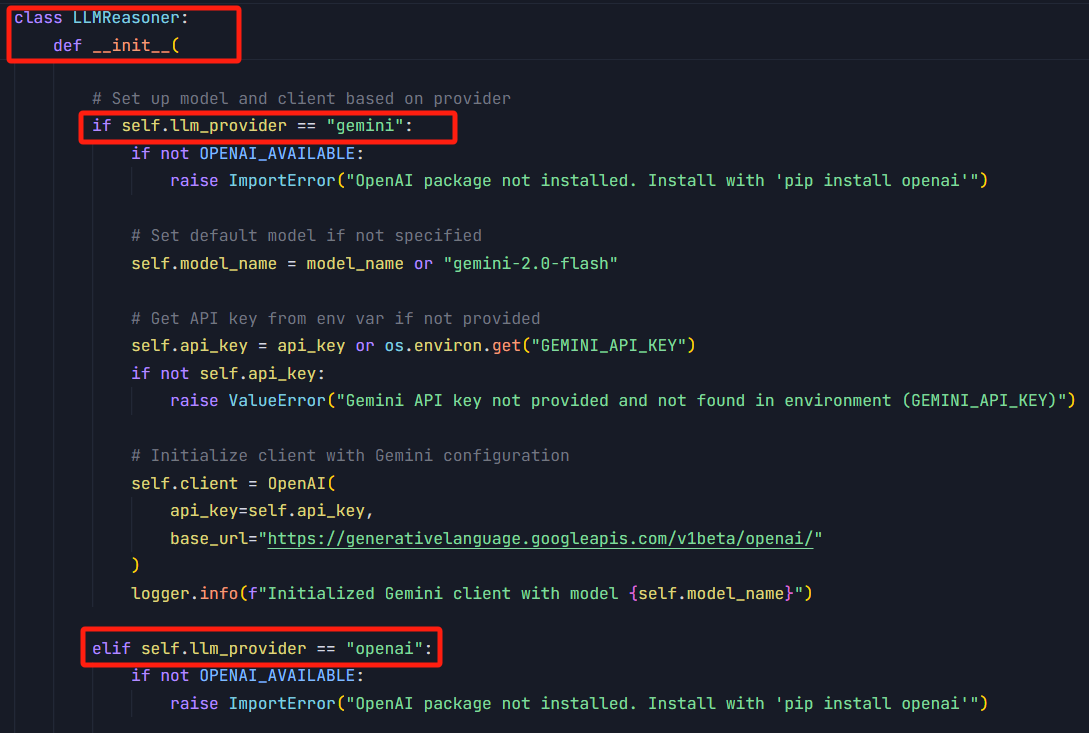
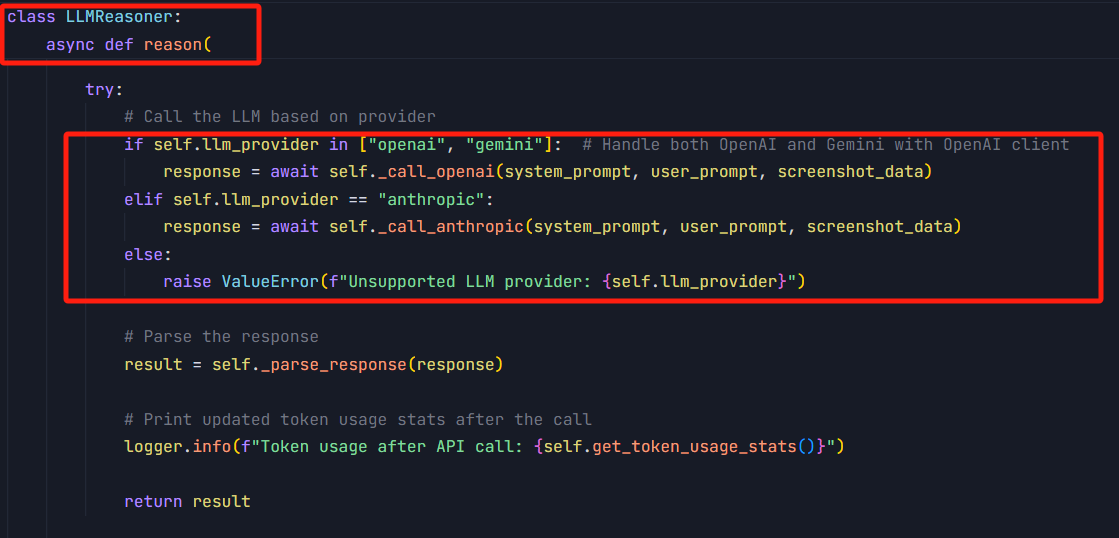
这种方案,架构相对简单,但是会导致init和reason这俩方法中,充斥着if else语句块。要新增对其它大模型的支持,需要修改不同的地方。
方式二、工厂类工厂模式
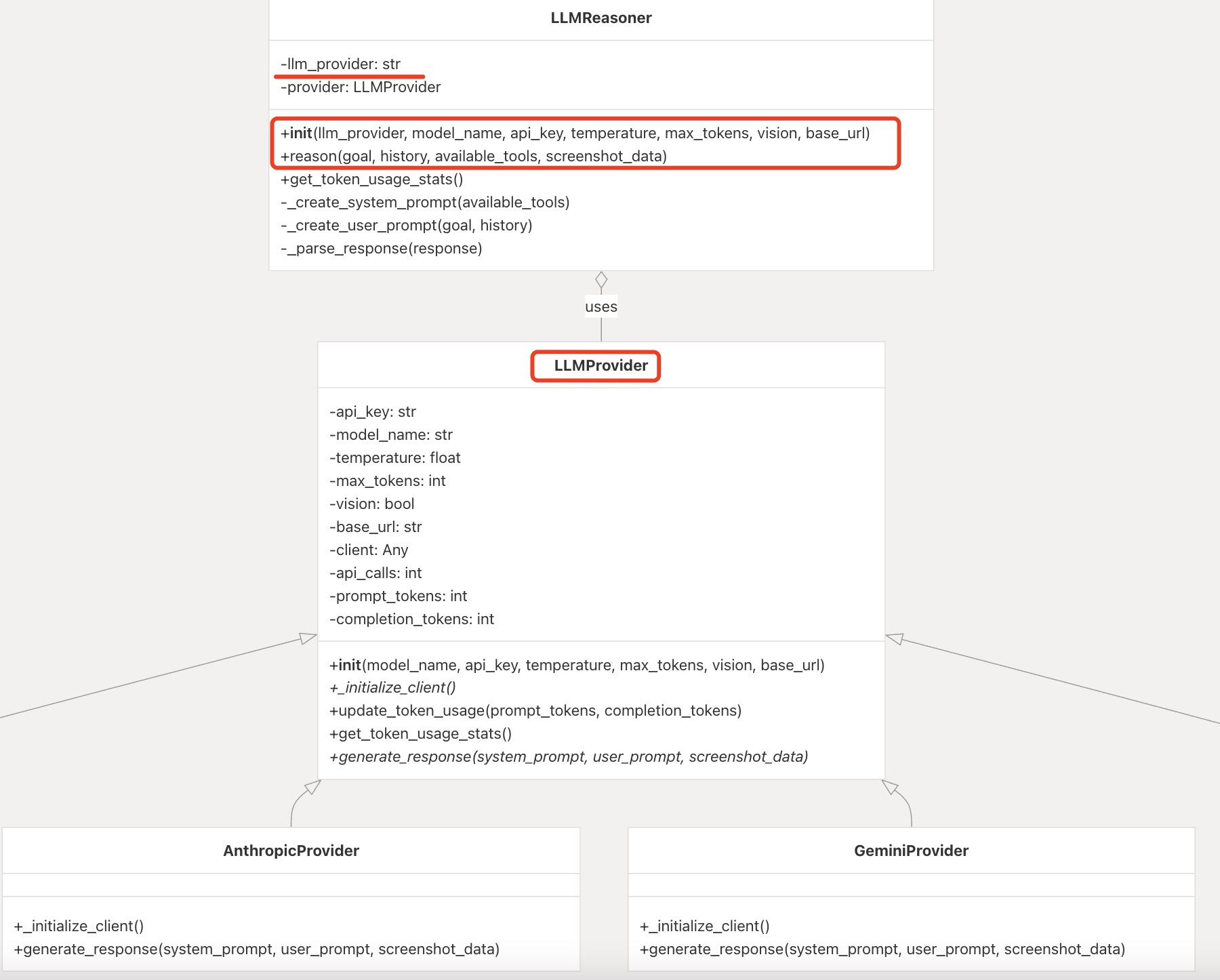
- 引入基类LLMProvider
- 每当要支持新的大模型时,比如deepseek,就新增一个子类DeepseekProvider,把deepseek的初始化和推理逻辑封装在_initialize_client()和generate_response(system_prompt,user_prompt,screenshot_data)中
- 这样一来,LLMReasoner的init和reason方法中,就不再硬编码各个大模型的初始化和推理逻辑,仅调用基类LLMProvider的_initialize_client和generate_response即可。

方法二比方法一更符合开闭原则
开闭原则(The Open/Closed Principle, OCP) 规定,“软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的”。在方法二中,新增对deepseek的支持,只需要新增一个子类(扩展),不再需要修改LLMReasoner的init方法和reason方法。这样更符合开闭原则,对原有逻辑的改变更少,为了新增一个逻辑,把原有逻辑改坏的概率也更小。
大模型初始化中的工厂模式